I was involved in a wide-ranging discussion of interfaces-vs-implementations, classes-and-sub-classes, Liskov substitutability, covariance, and what-not, with a colleague, when I was surprised by a Java behavior.
To explain what was surprising to me, consider the following program. To understand this program, you probably need to know that class
String extends class
Object, and implements the interface
Comparable.
import java.util.List;
import java.util.ArrayList;
public class parm
{
public static void main(String args[])
{
Object object = new Object();
String string = new String();
Comparable comparable = string;
String []stringArray = new String[1];
Object []objectArray = new Object[1];
List<String> stringList = new ArrayList<String>();
List<Object> objectList = new ArrayList<Object>();
ArrayList<String> stringArrayList = new ArrayList<String>();
ArrayList<Object> objectArrayList = new ArrayList<Object>();
if (object.getClass().isAssignableFrom(string.getClass()))
System.out.println("Object = String is OK");
if (string.getClass().isAssignableFrom(object.getClass()))
System.out.println("String = Object is OK");
if (comparable.getClass().isAssignableFrom(string.getClass()))
System.out.println("Comparable = String is OK");
if (objectArray.getClass().isAssignableFrom(stringArray.getClass()))
System.out.println("Object[] = String[] is OK");
if (stringArray.getClass().isAssignableFrom(objectArray.getClass()))
System.out.println("String[] = Object[] is OK");
if (objectList.getClass().isAssignableFrom(stringList.getClass()))
System.out.println("List<Object> = List<String> is OK");
if (stringList.getClass().isAssignableFrom(objectList.getClass()))
System.out.println("List<String> = List<Object> is OK");
if (objectArrayList.getClass().isAssignableFrom(stringArrayList.getClass()))
System.out.println("ArrayList<Object> = ArrayList<String> is OK");
if (stringArrayList.getClass().isAssignableFrom(objectArrayList.getClass()))
System.out.println("ArrayList<String> = ArrayList<Object> is OK");
objectArray = stringArray;
}
}
Before you compile and run the above program, try to guess what it's going to print out.
Well, I'm going to spoil it for you. Here's what it prints out:
Object = String is OK
Comparable = String is OK
Object[] = String[] is OK
List<Object> = List<String> is OK
List<String> = List<Object> is OK
ArrayList<Object> = ArrayList<String> is OK
ArrayList<String> = ArrayList<Object> is OK
The first few lines of output make sense; they correspond quite well to my simple-minded understanding of the
Liskov substitution principle.
And the substitution principle (also often called the IS-A principle), seems to hold for simple Java arrays, too. A
String array can be assigned to an
Object array, but not vice versa.
However, when we get to parameterized collection types, things start to go a little funky. All of a sudden the isAssignableFrom method seems to disregard the concrete type argument (
<String> or
<Object>) and just returns TRUE, indicating that the various parameterized list types should all be assignment compatible.
But they are not!
If you try to compile the following code:
stringList = new ArrayList<Object>();
objectList = new ArrayList<String>();
stringArrayList = new ArrayList<Object>();
objectArrayList = new ArrayList<String>();
You get:
parm.java:41: incompatible types
found : java.util.ArrayList<java.lang.Object>
required: java.util.ArrayList<java.lang.String>
stringArrayList = new ArrayList<Object>();
^
parm.java:42: incompatible types
found : java.util.ArrayList<java.lang.String>
required: java.util.ArrayList<java.lang.Object>
objectArrayList = new ArrayList<String>();
So what is going on here? Are the types assignable, or not?
After thinking about this for a while, I find that I can't really explain the behavior of the
Class.isAssignableFrom method on parameterized types, but I do think that the behavior of the parameterized types is reasonable.
A
List<String> is not a sub-type of a
List<Object>, because a
List<Object> is a type which allows an instance of any type of object to be added to it, while a
List<String> is a type which only allows instances of type
String to be added to it. So the
String list does not implement the same contract as the
Object list, and so cannot be considered a sub-type of it, and cannot be casually assigned without a cast.
So I think that the Java compiler is doing something reasonable here, but it sure is complicated.
Here's a nice short article that tries to explain the behavior in clear terms.
And, the next time you are at a cocktail party, and want to wow-em, you can casually say:
In Java, parameterized types are not covariant.
And just watch everybody's jaw drop with respect :)
 The trailhead is at 9,180 feet, our trail crested at 11,200 feed, and we spent most of our time at 10,975 foot Baboon Lake. Our trip route was similar to the trip marked on this map.
The trailhead is at 9,180 feet, our trail crested at 11,200 feed, and we spent most of our time at 10,975 foot Baboon Lake. Our trip route was similar to the trip marked on this map.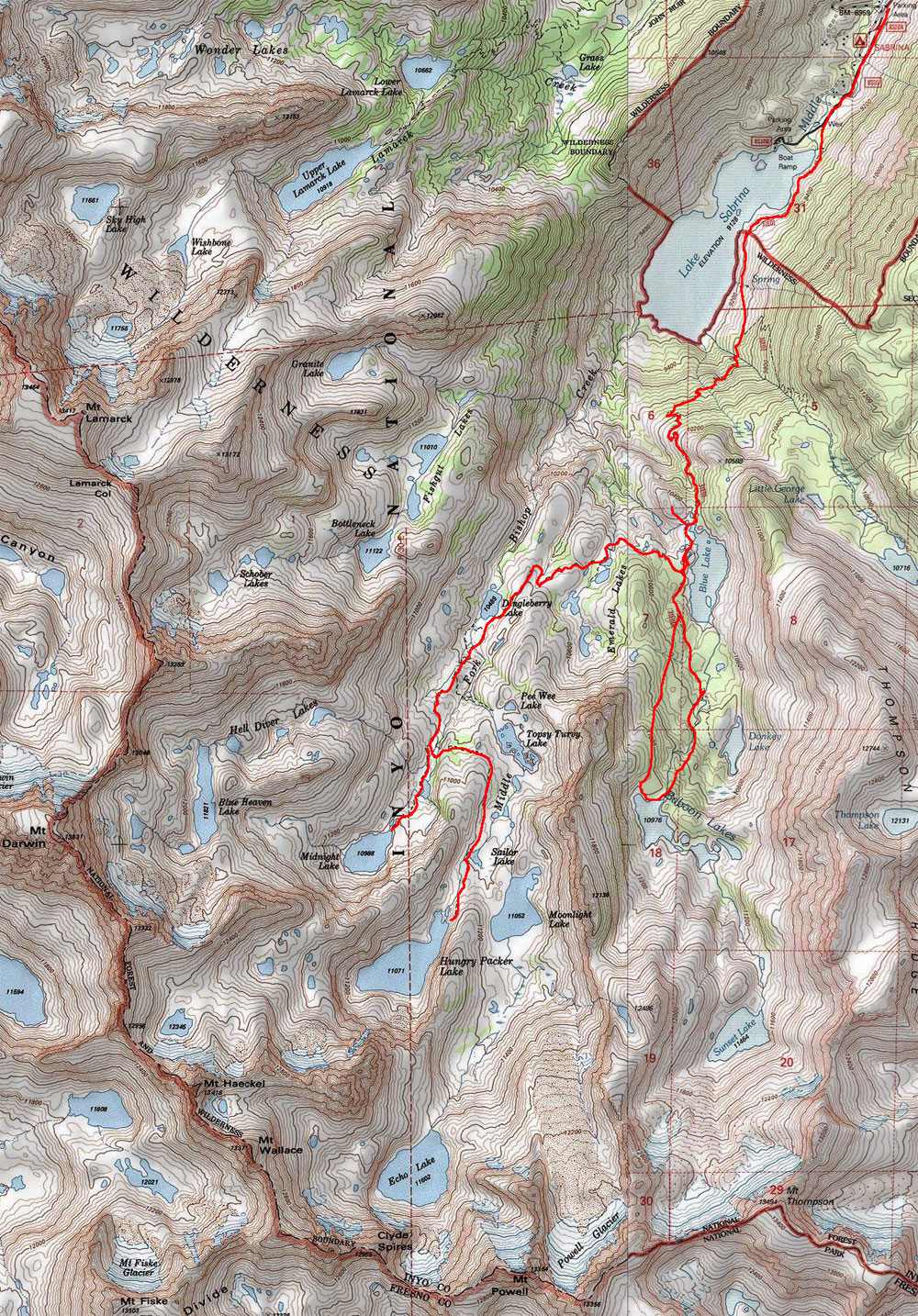{kind=link}


